Content Publisher Ingest API
Pantheon Content Publisher currently supports integration with Google Docs as a third-party content source. This documentation provides the guidelines for integrating any content source with Pantheon Content Publisher using RESTful APIs. It provides comprehensive setup instructions, detailed API endpoint specifications, request/response schemas, and practical examples with contextualised use cases.
- A website connected to Pantheon Content Publisher that can be used to render your content
- An active Content Publisher collection used by the website above
- A valid Content Publisher authentication token to perform authorised REST API operations.
- Content in HTML or Markdown format exported from the chosen content source.
Authentication is facilitated through Content Publisher-issued tokens. Developers must obtain and utilize valid tokens in API requests to ensure secure and authorised access. Token management, including creation and revocation, is handled via the Content Publisher CLI or through the Admin Interface (see here).
Description: This endpoint enables the creation of new Articles on a given site, functioning as individual web pages. Developers can create multiple Articles, thereby structuring the site's architecture effectively. Site organization and content management can be administered through the Admin dashboard.
POST /articles/create
{
"title": string, // title for the article
"siteId": string, // the site where the article will be created
"metadataFields": object, // any metadata to be provided for the article
"tags": []string, // tags that can be used as keywords to search for the article
"contentType": string // The article type. Eg: blog, documentation etc.
}
Response :
Success :
201 CREATED
Error :
401 UNAUTHORISED :
Invalid token provided
403 FORBIDDEN :
Token / User does not have the necessary permissions.
400 BAD_REQUEST :
The API returns a 400 status if the schema of the request data is invalid.
If the siteId is invalid.
If the metadata provided is not as per the schema configured on the site.
Description: This API endpoint enables content ingestion, allowing users to submit web content for articles in either HTML or Markdown format. It supports content ingestion for both real-time previews and publishing to production.
Note: This endpoint only accepts requests with a maximum body size limit of 10MB. If your content exceeds this limit, consider offloading inlined images and such to an external host.
POST /articles/{articleId}/ingest
{
"content": string, // stringified html / markdown content
"publishLevel": string, // realtime or prod
"contentType": string, // html or markdown
"docName": string, // name of the document, used internally for versioning
"docRevisionDate": number // update time of the document, used internally for versioning
}
Response:
Success :
204 NO_CONTENT
Error :401 UNAUTHORISED :
Invalid token provided
403 FORBIDDEN :
The user does not have the necessary permissions.
400 BAD_REQUEST :
The API returns a 400 status if the schema of the request data is invalid.
The API will return a 400, if the article is not connected to a site.
404 NOT_FOUND :
The API will throw a 404 if the provided articleId is invalid.
422 UNPROCESSABLE_CONTENT :
The API will return 422 status, if the provided content could not be Ingested.
Description: This endpoint allows you to disconnect an Article from a site. If the disconnected Article is a parent to other Articles, those child Articles will become unassigned and appear under the "No-section" category in the content management dashboard. They can be reorganized and managed through the Collections dashboard.
POST /articles/{articleId}/disconnect
No Request body required
Response :
Success :
204 NO_CONTENT
Error :401 UNAUTHORISED :
Invalid token provided
403 FORBIDDEN :
The user does not have the necessary permissions.
400 BAD_REQUEST :
The API will return a 400, if the article is already disconnected.
404 NOT_FOUND :
The API will return a 404, if the articleID provided is invalid.
Usage Example
To proceed with this example, you would need a Pantheon site connected with Content Publisher. If you don’t have a site setup yet, you can do so by following the guide provided here.
Let's create an article on the site :
You can create an Article by making a request to the createArticle endpoint detailed above.
An example request using CURL would look like this.
curl --location 'https://api.content.pantheon.io/articles/create' \
--header 'Authorization: Bearer YOUR_MANAGEMENT_TOKEN' \
--header 'Content-Type: application/json' \
--data '{
"title": "Test Article 2",
"siteId": "testSiteID_1",
"metadataFields": {
"slug": "test_article_slug_11",
"Maturity": "Low",
"Birthday": 1737763200000,
"image": "https://storage.googleapis.com/pcc-staging-user-uploads/8a3f8f73-9fed-4005-b7e8-8908490e7d24",
"author": "kiran",
"Text area": "lorem ipsum lorem",
"description": "lorem ipsum lorem"
},
"tags": ["tag1", "tag2"],
"contentType": "blog"
}'
Response :
201 Created
{"id":"b9Rd78IJj4iy3EIcYcbh"}
The API returns a unique Identifier in the response, for the article you created. You can use this Article Id for content Ingestion.
Once you have the articleId, you can make content Ingestion requests. Most Document processors / content management tools like Google Docs or Notion etc. provide facilities to export the document content into Html or markdown. The exported content can be directly channeled to Content Publisher via the Ingest API.
Lets say, you wanna set the following html content for the Article.
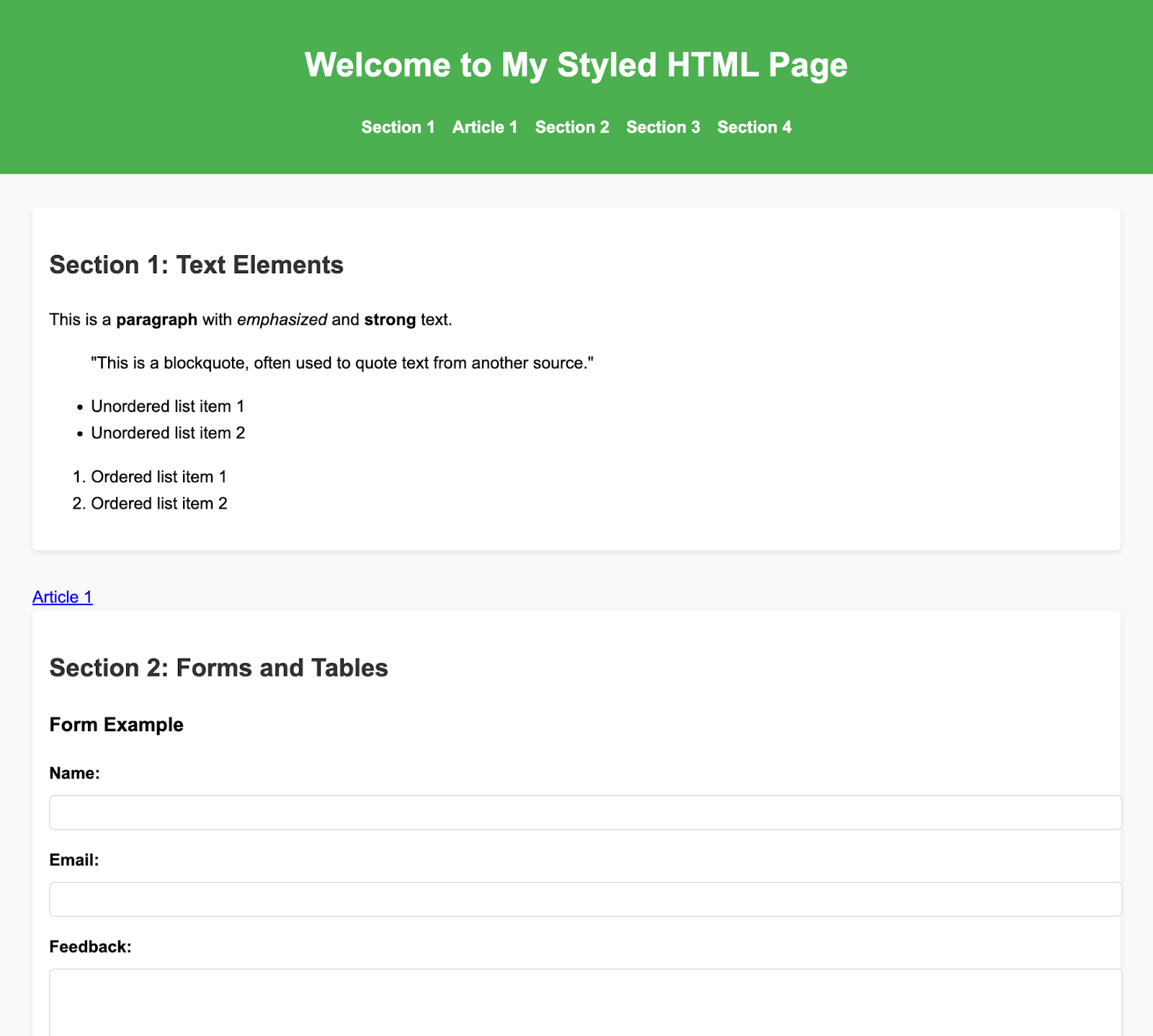
You would need to stringify the HTML content, to escape the quotes and add newline chars, essentially converting the html content into a single line string, making it convenient to be included in the request body. This can be achieved with built-in APIs on most programming languages.
Fr eg: In javascript, JSON.stringify() would do.
A sample CURL request for the above html content would look like this.
curl --location 'https://api.content.pantheon.io/articles/b9Rd78IJj4iy3EIcYcbh/ingest' \
--header 'Authorization: Bearer YOUR_MANAGEMENT_TOKEN' \
--header 'Content-Type: application/json' \
--data '{
"content": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\n <title>Styled Complex HTML Page</title>\n <style>\n body {\n font-family: Arial, sans-serif;\n</style>
..
.
<section id=\"section4\">\n <h2>Section 4: Images</h2>\n <div class=\"image-gallery\">\n <figure>\n <img src=\"https://picsum.photos/300\" alt=\"Random Image 1\">\n <figcaption>Figure 1: A random image from Picsum.</figcaption>\n </figure>\n <figure>\n <img src=\"https://picsum.photos/400\" alt=\"Random Image 2\">\n <figcaption>Figure 2: Another random image from Picsum.</figcaption>\n </figure>\n </div>\n </section>\n </main>\n\n <footer>\n <p>© 2024 My Styled HTML Page. All rights reserved.</p>\n </footer>\n</body>\n</html>",
"publishLevel" : "prod",
"contentType": "html",
"docName": "testDoc",
"docRevisionDate" : 1738742071112
}'
* The content string is truncated and meant for reference only. To try out the working sample request, refer to the Postman collection attached below.
The docName and docRevisionDate values are used to maintain the versioning information for the Article.
Response :
204 NO_CONTENT
All the APIs described here are synchronous in nature. Therefore, once the API has returned the response, the content is processed and updated in the Article successfully.
The updated Article would look like this, for reference.
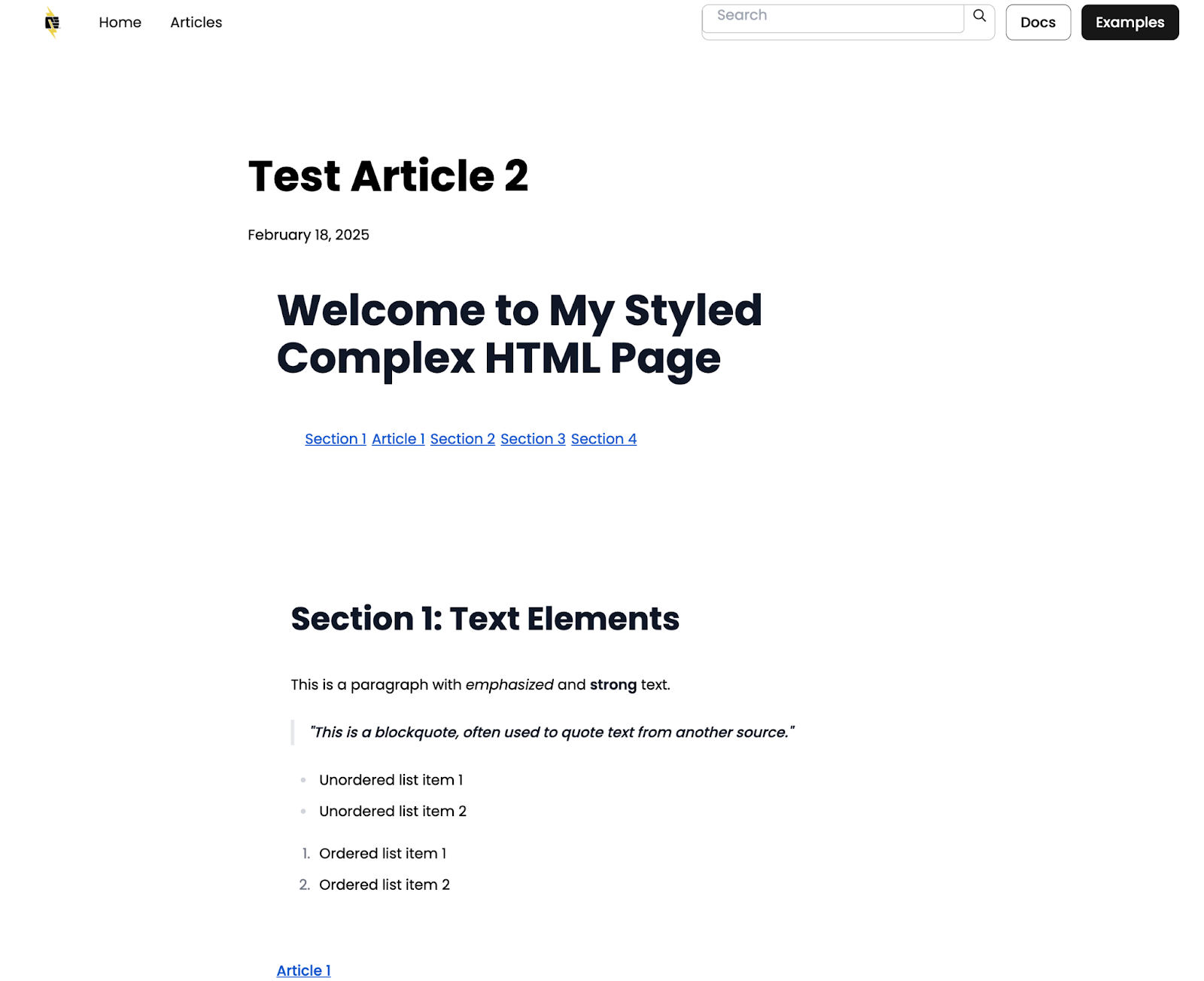
Although any standard HTML or Markdown can be ingested as valid content, we impose specific constraints to ensure consistency and provide a better developer experience, reducing the likelihood of unexpected outcomes during content processing.
To ingest Markdown content, It would be as follows.
curl --location 'https://api.content.pantheon.io/articles/b9Rd78IJj4iy3EIcYcbh/ingest' \
--header 'Authorization: Bearer YOUR_MANAGEMENT_TOKEN' \
--header 'Content-Type: application/json' \
--data '{
"content": "# Ultimate Markdown Showcase\r\n\r\nWelcome to the **Ultimate Markdown Showcase**. This document contains a comprehensive example of Markdown elements, including headings, lists, code blocks, tables, blockquotes, HTML, math, footnotes, and more.\r\n\r\n---\r\n\r\n## 1. Headings and Text Formatting\r\n\r\n### 1.1. Basic Text\r\nThis is a paragraph with **bold text**, *italic text*, and ***bold italic text***. You can also use \\`inline code\\` to emphasize snippets.\r\n\r\n### 1.2. Escaped Characters\r\nUse backslashes to escape Markdown characters: \r\n\\*literal asterisks\\*, \\# not a heading.\r\n\r\n---\r\n\r\n## 2. Blockquotes and Nesting\r\n\r\n> **Blockquote Level 1:** \r\n> This is a blockquote containing several nested elements.\r\n> \r\n> ### Nested Heading in Blockquote\r\n> Even headings can be nested within blockquotes.\r\n> \r\n> - **Nested List in Blockquote:**\r\n> - First nested bullet\r\n> - Second nested bullet with `inline code`\r\n> - Deeper nested list:\r\n> 1. Ordered item one\r\n> 2. Ordered item two\r\n> \r\n> > **Blockquote Level 2:** \r\n> > > **Blockquote Level 3:** \r\n> > > A deeply nested blockquote with a Logo\"){width=\"500\" height=\"300\"} 9. Conclusion\r\n\r\nMarkdown is a **powerful** tool for creating rich documents with simple syntax. Whether you'\''re including code, tables, math, or nested structures, Markdown offers a flexible way to format your content.\r\n\r\n---\r\n\r\n*End of the Markdown Showcase.*",
"publishLevel" : "prod",
"contentType": "markdown",
"docName": "testDoc",
"docRevisionDate" : 1738742071112
}'
Note : the contentType field needs to be set to markdown
Response :
204 No Content
Markdown content must also be escaped and stringified similarly to the HTML content shown in the example above.
The API supports both CommonMark and GFM (GitHub Flavored Markdown) specifications. Additionally, attributes can be set on elements, such as specifying the width and height for an image element, as demonstrated below.
{width="500" height="300"}
Once the content is ingested, the page would like this :
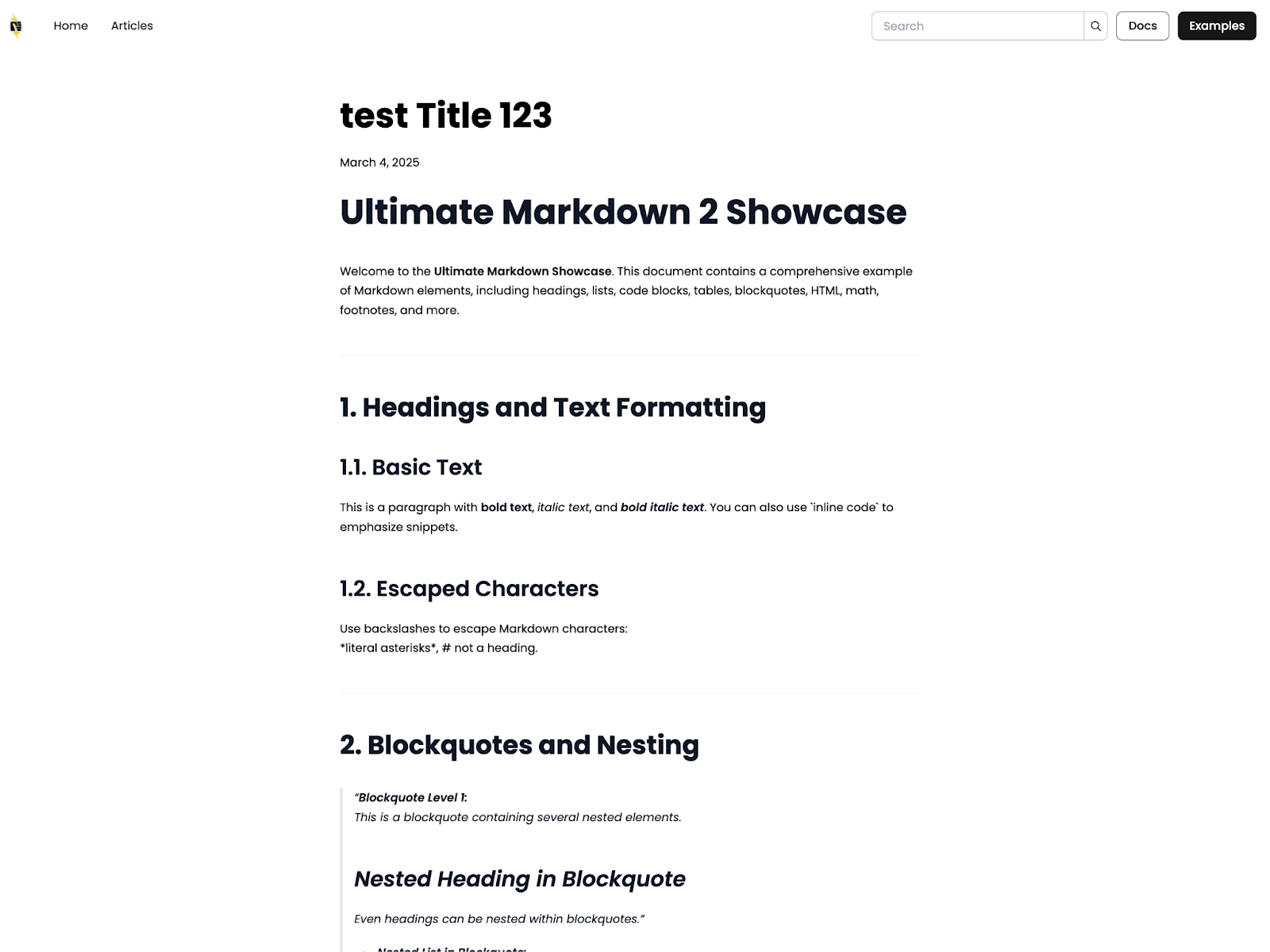
You can use this Postman collection to try out the API on your site.
Make sure to configure all the required environment variables in the postman Application once the file is loaded.
Images and other assets passed to Content Publisher via the ingest API are treated the same way as Content Publisher treats images passed from Google Docs. External image links are replaced with link to our CDN. Both external images as well as inline Base64 images are moved to the CDN.